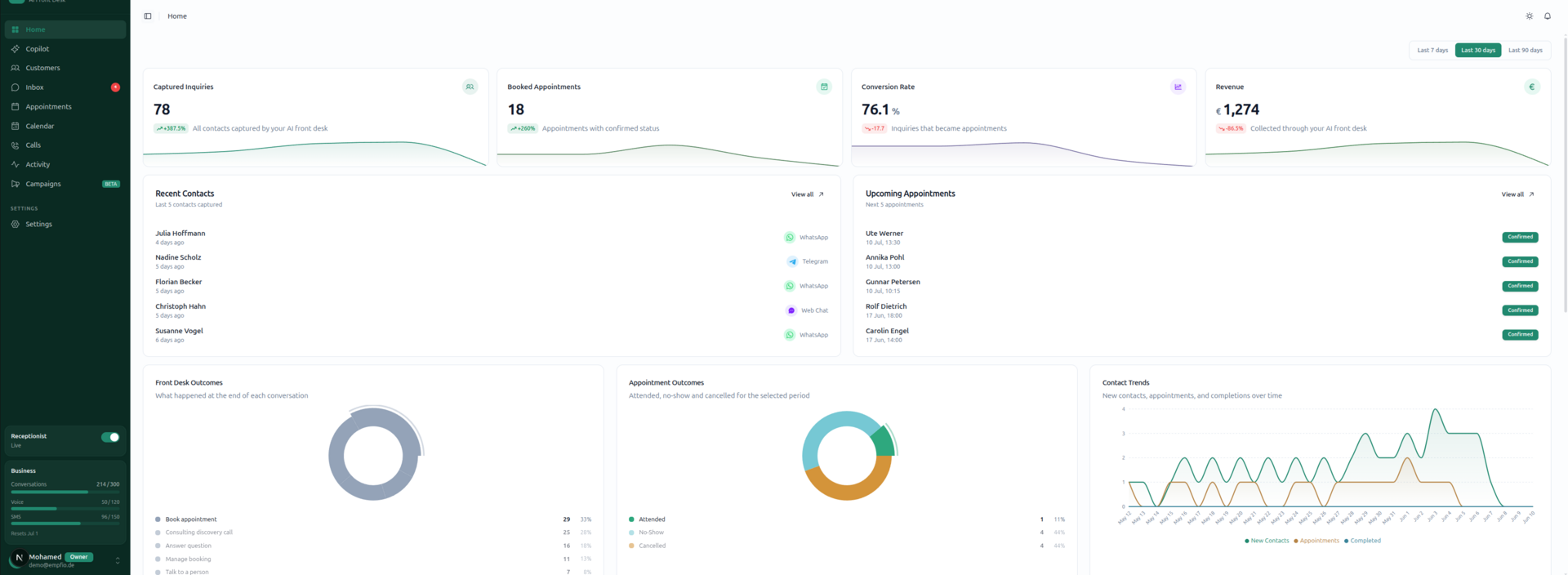
Empfio is an AI front desk for appointment-based businesses — salons, dental practices, trades, consultants. Customers call or message; the AI answers, books, reschedules, takes payments, and hands off to a human when it should. The business runs everything from one dashboard: conversations, customers, appointments, calendar, calls, knowledge, billing, and team.
I designed, built, and deployed it alone in three months — architecture, backend, voice pipeline, frontend, infrastructure, and the daily work of operating it in production. It is live at empfio.de.
This page is a technical tour of how it works.
The design principle
One rule shaped every architectural decision: code owns the control flow, the LLM owns the language.
The LLM never decides what the business process is. It does not invent booking rules, choose escalation policy, or decide which tools exist. Deterministic code — typed tools, classifiers, database constraints, plain configuration — owns all of that. The LLM does the two things it is genuinely good at: understanding what a person means, and saying the right thing back.
This sounds obvious. Most agent demos do the opposite: one giant prompt, the model freestyles the workflow, and it works right up until it doesn't. Everything below is this one principle applied repeatedly.
Architecture
Customer channels Phone / browser voice
WhatsApp / Telegram / web chat / SMS SIP / WebRTC
| |
v v
FastAPI backend <-------------------- Voice service (LiveKit)
DDD domains, auth, billing, persistence, channel adapters
|
| classify topic, gather context, enforce org state
| then call the in-process agent
v
Agent library (empfio_agent_lib)
Stateless per-turn LLM caller, topic-driven tools, structured extraction
|
v
PostgreSQL 16 + Redis 7 + Celery + Qdrant
|
v
Next.js dashboard, marketing site, docs
It is a monorepo: a FastAPI backend (Python 3.12, async SQLAlchemy 2.0), a LiveKit voice service, a web scraper for knowledge ingestion, and four Next.js apps (dashboard, marketing, docs, payments), plus two shared packages. Sixteen containers in production behind Traefik with automatic HTTPS, deployed to AWS with Ansible.
The agent is a library, not a service. The backend imports empfio_agent_lib and calls it in-process — no agent HTTP hop, no separate agent container, one failure domain. At this scale the LLM round-trip dominates latency anyway; a network hop between "backend" and "agent" would buy nothing and cost state consistency. The agent itself is stateless per turn: every turn is a fresh run with externally managed message history, which makes it trivially safe to restart and horizontally scale with the backend.
Topics: behaviour as configuration
The signature idea in Empfio is the Topics system. AI behaviour is configured through declarative "behaviour cards", not code:
| Field | Purpose |
| --- | --- |
| classifier_description | When this behaviour should activate |
| scope | Hard boundaries the AI must not cross |
| instructions | Step-by-step playbook |
| allowed_actions | Which tools the AI may call in this topic |
| required_fields | Information that must be collected before completion |
| auto_escalate_if | Plain-language conditions that force human handoff |
A dental emergency, a salon reschedule, and a trades call-out are different Topics on the same engine. Adding a vertical means writing configuration, not shipping code. Topics are per-channel gateable, prioritised for tie-breaking, and backed by a template system (with translations — the product is German-first) so a new organization starts from sensible industry defaults.
Every topic switch is recorded with its confidence score and reasoning in a TopicTransition audit table — so when classification misbehaves, there is data to debug it instead of vibes.
Anatomy of a single turn
What happens when a customer sends "can I move my appointment to Thursday?":
- A channel adapter normalizes the message. WhatsApp (Meta Cloud API), Telegram, SMS (Twilio), web chat, and voice all funnel into one inbound path that resolves the organization, customer, and conversation.
- Three small-model calls run in parallel (
asyncio.gather, all on gpt-4o-mini): a topic classifier, an escalation-policy check that evaluates the topic's plain-Englishauto_escalate_ifcondition and can short-circuit the whole turn to a human, and a field extractor that pulls structured data (names, dates, addresses) out of the message before the main model ever runs. - The topic classifier is rate-limited by design. A classified topic sticks to the conversation in Redis for 30 minutes; follow-up turns skip re-classification entirely unless a new candidate beats a switch threshold. Multi-turn flows stay cheap and stable instead of re-deciding the topic on every message.
- The main model runs with topic-scoped tools. GPT-4o by default, routed through LiteLLM with Anthropic, Groq, and Ollama as supported paths. The topic's
allowed_actionsfilters which tools the model can even see. - Persistence is fire-and-forget through an outbox. Usage events and audit records are written to an outbox table and drained by a Celery task — a backend crash mid-turn loses nothing, and the agent never waits on bookkeeping.
The tools
Two agents share one typed-tool architecture (Pydantic AI — async functions with injected, typed dependencies):
- The customer agent has 21 tools: lead capture and lookup, availability search, booking create/cancel/reschedule, urgency classification, address and custom-field capture, marketing consent, rich interactive options (buttons/lists on channels that support them), graceful voice hangup, and escalation to a human.
- The owner copilot has 31 tools — this is the second agent, living inside the dashboard. The owner can ask it to resolve escalations, bulk-manage bookings, block staff time, update business hours, manage the knowledge base, or pull analytics. Mutating actions are approval-gated: the copilot proposes, the human confirms.
Tool calls use content-derived idempotency keys — a booking creation derives its key from the actual booking content, not a request ID. A timed-out call replayed by a retry cannot double-book or duplicate a customer record. With non-deterministic models in the loop, the tool layer is where determinism gets enforced.
Voice
Voice is its own service on the LiveKit Agents SDK, but it never bypasses the backend — every voice turn relays through the same topic classification, billing, and persistence path as a WhatsApp message. One brain, five mouths.
The pipeline: Deepgram Nova-3 for STT, ElevenLabs turbo (or Cartesia) for TTS, Silero VAD for turn detection, and Telnyx SIP through LiveKit for real phone numbers. Browser calls from the marketing site use WebRTC against the same stack.
The part I'm most proud of is warm transfer: when the AI escalates a live call, the caller is muted onto hold music while the system dials the business owner over the SIP trunk, detects voicemail (so it doesn't brief an answering machine), lets the agent privately brief the human on who is calling and why, and then bridges everyone together. Built on raw SIP participant control, since self-hosted LiveKit doesn't offer managed transfer.
Knowledge and RAG
Each organization gets a private knowledge base: documents ingested from Google Drive, OneDrive, Dropbox, or scraped from their website by a dedicated Chromium-based scraper service, then chunked, embedded (OpenAI text-embedding-3-small), and stored in Qdrant with organization-scoped payload filters for hard tenant isolation. Retrieved chunks are injected as a stable prompt prefix — deliberately positioned so the LLM provider's prefix cache survives across turns and topic switches.
Running it in production
Boring on purpose, and boring is the feature:
- Observability: Prometheus metrics across the stack — topic-transition confidence histograms, STT/TTS latency, per-call token counters, DB pool stats — plus structured JSON logging (structlog) and optional Langfuse tracing of every agent run.
- Billing: Stripe subscriptions with metered usage (conversations, voice minutes, SMS) and plan gates enforced server-side; a billing preflight rejects calls before they cost money if an org is over limit.
- Resilience choices: rate limiting fails open if Redis is down (availability over defense for paying customers), migrations run as a one-shot container before the backend starts, and every service has health checks.
- Deploys: images built to ECR, rolled out by an Ansible playbook — clone-to-running on a fresh server is one playbook run.
What I'd harden next
Operating it surfaced the next layer of work, mostly multi-tenant hardening: per-organization rate limiting on the agent endpoint (today it is per-IP), wiring the voice service's finalization drain into SIGTERM so rolling restarts can never lose a transcript, and end-to-end distributed tracing across backend → agent → voice. Knowing precisely where your system is weakest is what running it in production buys you.
Skills: LLM Agents, Tool Calling, Pydantic AI, LiteLLM, Voice AI, LiveKit, Deepgram, ElevenLabs, SIP Telephony, RAG, Qdrant, FastAPI, PostgreSQL, Redis, Celery, Next.js, Stripe, Prometheus, Langfuse, Docker, Traefik, Ansible